Özet :
Bu çalışma Epileptik ve Normal EEG verilerinin , Yapay Sinir Ağları ile ve PoincarePlot2D metoduyla çıkarılan öznitelikleri kullanarak sınıflandırılması üzerinedir.
Giriş :
Epilepsi Dünya nufusunun %1’ni etkileyen bir rahatsızlıktır. Beynimiz milyarlarca sinir hücresinden oluşur ve bu hücreler üzerinde sürkeli bir elektiriksel iletişim vardır. Epilepside Beynin normalde çalışması ile ilgili elektriğin, aşırı ve kontrolsüz yayılımı sonucu oluşan ve herhangi bir uyarı olmaksızın tekrarlayan, çoğunlukla geçici bilinç kaybına neden olan bir hastalıktır.
EEG yani Elektroensefalografi beynin elektriksel aktivitesini ölçmek için kullanılan bir metoddur. Aynı zamanda epilepsili hastaları ve şüphe oluşturan nöbet bozuklukları olan hastaları incelemekte kullanılan önemli bir tetkiktir.
Uzun süreli EEG sinyallerinin incelenmesi ve istenen bilgilerin çıkarılması oldukça uzun zaman alan ve tecrübe gerektiren bir iştir. Bu yüzden Otomatik EEG analiz sistemleri üzerinde çalışmalar yapılmaktadır. Bu çalışmada benzeri bir sistem üzerinedir.
Metod :
Pek çok Yapay Zeka uygulamasında olduğu gibi ilk aşamalardan biri Öznitelik Çıkarma işlemidir. Biz bu çalışmada PoicarePlot2D diye adlandırdığımız -deneysel- bir metodu uyguladık.
Poicare Plot adını fransız matematikçi H. Poincare den alan bir metoddur. Basitçe anlatırsak
X1, X2,… Xn
şeklindeki bir zaman serisinin 2 boyutlu bir koordinat sisteminde sırayla
(X1, X2 ) , (X2, X3 ) , (X3, X4) , …. , (Xn-1, Xn )
noktalarının çizilmesidir.
Mesela Basit bir sinus serisinin
Poincare Grafiğine dönüşmüş hali
Şeklinde görünür.
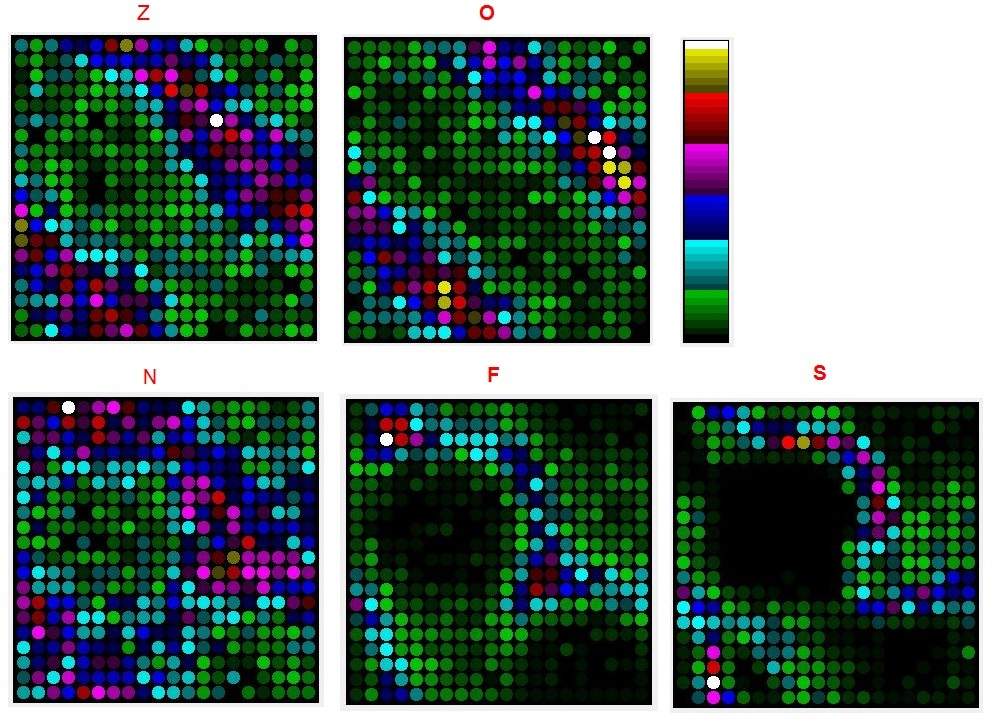
Öznitelik çıkarma işleminde veri seti ile Poincare Grafiği oluşturulur ve çıkan şeklinden yola çıkılarak 20×20 lik bir matris oluşturulur.
Sinus verisi için çıkarılan öznitelik matrisi bu şekildedir.
İkinci aşama ise çıkarılan özniteliklerin seçilecek bir Yapay zeka Algoritmasıyla sınıflandırılmasından ibarettir. Biz çalışmamızda Yapay Sinir Ağı metodunu kullandık. YSA için FANN kütüphanesini kullandık . Eğitimi ve sonuçların testi içinde FannTool programından faydalandık.
Veri Seti :
Çalışmamızda kullandığımız , Bonn Üniversitesinde, Epileptoloji Bölümünün hazırladığı bir EEG veri setidir. Verilere bu adresden ulaşabilirsiniz.
Bütün kayıtların alımı 128 kanallı kayıt sisteminde 12-bit A/D dönüstürücü ile yapılmıştır. Örnekleme frekansı 173.61 Hz dir. Band-geçiren filtre aralıgı ise 0.53–40 Hz (12 dB/octave) dir.
5 sınıfa ayrılmış veriler var ve her sınıfda 100 adet veri dosyası var her dosyada 4096 değer var.
- Sınıf A : Sağlıklı Gönüllülerden alınmış Göz Açık ( Z )
- Sınıf B : Sağlıklı Gönüllülerden alınmış Göz Kapalı ( O )
- Sınıf C : Epilepsi hastası Kriz dışında Epileptik olmayan bölgeden ( N )
- Sınıf D : Epilepsi hastası Kriz dışında Epileptik olan bölgeden ( F )
- Sınıf E : Epilepsi hastası Kriz esnasında ( S )
Uygulama :
Öncelikle Veri setimizden
PoincarePlot2D metoduyla
Öznitelik çıkarma işlemini gerçekleştiriyoruz.
Bütün Sınıflandırma işlemini tek YSA ile yapmaya kalkıştığımızda Yaptığımız çeşitli denemeler sonucunda Test için ulaşabildiğimiz en yüksek başarı % 70 lerin biraz üstünde oluyor.
Bu yüzden bizde sınıflandırma işlemini parçalara ayırıyoruz ve her parça için ayrı YSA eğitiyoruz.
Bütün sınıflandırmayı 3 YSA ile gerçekleştiriyoruz
Birinci YSA ; EEG verisi Sağlıklı birinden mi Epilepsi hastasından mı alınmış kararını veriyor
500 veriden 375’ini eğitim ve 125’inide test için kullanıyoruz.
400 giriş 1 Çıkış
İkinci YSA ; İlk YSA sonucunda Epilepsi Hastasından alınmış bir EEG ise, Verinin alınma konum ve yerine karar veriliyor.
- Kriz sırasında,
- Kriz dışında, Epileptik taraftan
- Kriz dışında, Epileptik olmayan taraftan
Kriz dışında 3 durum var. 300 veriden 225’ini eğitim ve 75’inide test için kullanıyoruz.
400 giriş 3 Çıkış
Üçüncü YSA ; İlk YSA sonucunda Sağlıklı bireylerden alınmış bir EEG ise Göz Kapalımı, Açıkmı kararını veriyor. 200 veriden 150’ini eğitim ve 50’inide test için kullanıyoruz.
400 giriş 1 Çıkış
Sonuç :
YSA ile yaptığımız bütün sınıflandırmalarda ulaştığımız sonuç;
hem Eğitim hemde Test verileri için %100 başarı
Aynı veri seti kullanılarak yapılan diğer çalışmaların başarıları aşağıdaki tabloda görülmektedir.
Yapılmış olan benzeri çalışmalar hakkındaki detaylı bilgiye
Automated Epileptic Seizure Detection Methods: A Review Study
çalışmasından ulaşabilirsiniz yukardaki tabloda o çalışmadan alınmıştır.





























{kind=link}
Son Yorumlar